daikon
A mini-project to solve my own problem of looking up words/sentences in non-selectable Japanese texts using Optical Character Recognition (OCR).
Similar tools already exists (see manga-ocr), but I found them to be generally out-of-date, too complex, or overachieving, so I made my own that I can be in control of. A tool like this must be snappy, easy to use, and with minimal overhead not to break the flow of reading. Otherwise I'll just not use it.
Scroll to the end for example usage.
Motivation
Learning to read Japanese without furigana is in my eyes the final frontier of the language. Its presence is usually at the whim of the author, but if you want to read anything more serious than children's material, getting comfortable with raw kanji is essential.
You cant't "complete" Japanese though. No sane man knows all the kanji, but constant exposure will result in steady progress. I'm an advocate of not looking up a single unknown point. If the overall meaning is understandable, have faith that your brain will, over time, remember the patterns. Actively research a sentence only if it is mostly devoid of meaning as you're clearly lacking some fundamental knowledge.
We aquire language in one way, and only one way. Comprehensible input in a low anxiety environment. Dr. Stephen Krashen
I take Dr. Krashen's "Low Anxiety Environment" to also includes the tools you use. Learning a language should be fun, but if looking up a word or grammatical point is a struggle, so too will the learning be a struggle.
LLMs have already shown to be an amazing tool for language learning, providing explanations of grammar or sentence structure at your fingertips, but they don't (yet) support OCR, hence this project.
The Problem(s)
Take the following sentence presented with and without furigana.
- これが人類最後の絵になるかもしれないし。
- これが人類最後の絵になるかもしれないし。
Let's say you're a budding learner of Japanese and don't know what 人類最後 means (or that it is actually 2 independent words), and want to figure it out in the following scenarios.
Selectable Text
Without furigana, simply copy 人類最後 to Jisho! However, it is not so simple if you try to copy the same word with furigana, 人類最後. Ironically, what makes it easier to read also makes it annoying to look up.
Non-Selectable Text
Say what you will about manga, but for learning Japanese they provide an endless source of material from all levels and themes with the added benefit of always providing context through images. The only problem is that even now in 2023, digital format manga in neither PDF nor ePUB come with selectable text. They're all images!
The common way around this has been either drawing the kanji or looking it up using radical dictionaries, two methods that both of which have serious downsides and completely break the flow of reading.
The Project
OCR has (finally) become good enough that it can reliably work with both vertical and horizontally aligned Japanese sentences, with and without furigana. This opens the door for all kinds of neat tools that quickly capture unselectable text that can be processed by other tools, like dictionaries or LLMs.
I just picked some open-source JP OCR model from huggingface, made sure I could run it locally, then cooked up a bash script that sends the result to stdout or the clipboard. Pretty convenient. This allows for super useful things like OCR-ing a sentence with all kinds of unknown words and grammar, then maybe asking GPT "Translate and explain each grammatical component in the following sentence: OCR_OUTPUT" in seconds.
Usage
Simply call the bash script. This will send the processed text to stdout.
bash daikon.sh
I'd recommend you place it somewhere in path and call it using the --clipboard flag.
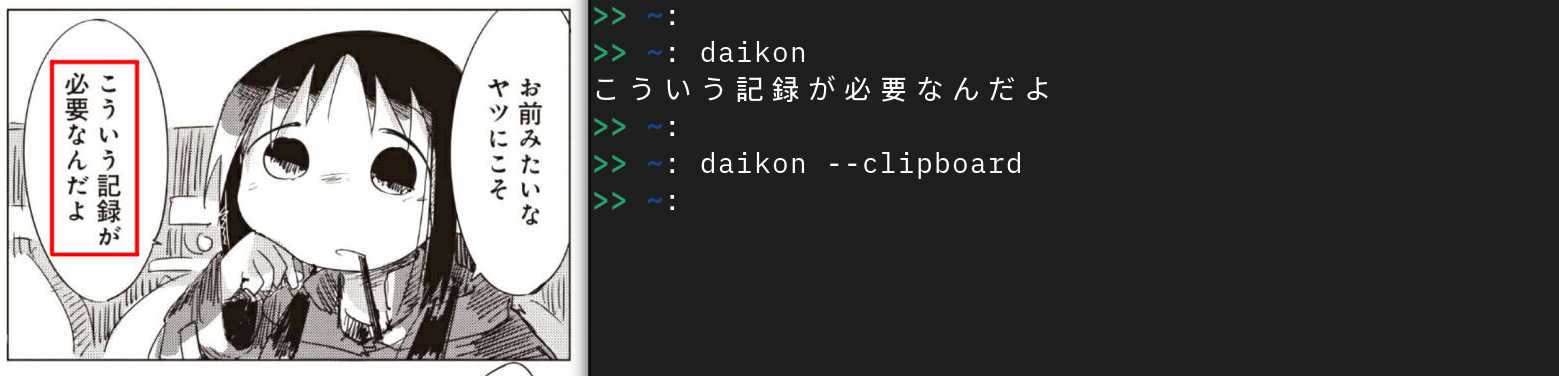
If you're running Yomichan in parallell you now essentially have an automatic OCR dictionary. How useful is that?! Now I can read without furigana in peace.